


在java中使用redis
一、redis客户端类型
| 类型 | 优缺点 |
|---|---|
| jedis | 以Redis命令作为方法名称,学习成本低,简单实用。但是]edis实例是线程不安全的,多线程环境下需要基于连接池来使用 |
| lettuce | Lettuce是基于Netty实现的,支持同步、异步和响应式编程方式,并且是线程安全的。支持Redis的哨兵模式、集群模式和管道模式。Spring默认支持此类型 |
| redisson | Redisson是一个底层基于Redis实现的分布式、可伸缩的Java数据结构集合。包含了诸如Map、Queue、Lock、semaphore、AtomicLong等强大功能(本文中未做介绍) |
springDateRedis 集成了jedis和lettuce
二、使用教程
1、jedis
jedis仓库地址:https://github.com/redis/jedis
首先创建一个maven工程,使用依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>4.1.1</version>
</dependency>
建立连接
void setUp() {
// 1、建立连接
jedis = new Jedis("127.0.0.1", 6379);
// 2、设置密码
jedis.auth("123456");
// 3、选择库
jedis.select(0);
}
操作redis
@Test
void testString() {
String set = jedis.set("name", "lisa");
System.out.println(set);
String name = jedis.get("name");
System.out.println(name);
}
@Test
void testHash() {
// 插入数据
jedis.hset("user:1","name","jack");
jedis.hset("user:1","age","18");
// 获取
Map<String, String> map = jedis.hgetAll("user:1");
System.out.println(map);
}
void tearDown() {
if (jedis != null){
jedis.close();
}
}
测试完整代码
package com.jedisTest;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import redis.clients.jedis.Jedis;
import java.util.Map;
public class JedisTest {
private Jedis jedis;
@BeforeEach
void setUp() {
// 1、建立连接
jedis = new Jedis("", 6379);
// 2、设置密码
jedis.auth("123456");
// 3、选择库
jedis.select(0);
}
@Test
void testString() {
String set = jedis.set("name", "lisa");
System.out.println(set);
String name = jedis.get("name");
System.out.println(name);
}
@Test
void testHash() {
// 插入数据
jedis.hset("user:1","name","jack");
jedis.hset("user:1","age","18");
// 获取
Map<String, String> map = jedis.hgetAll("user:1");
System.out.println(map);
}
@AfterEach
void tearDown() {
// 逻辑健壮性处理,结束后关闭连接,没有成功连接则不处理
if (jedis != null){
jedis.close();
}
}
}
总结
jedis最大优势就是调用方法名称和命令行名称一致,建议结合redis常用命令食用,也就不做过多演示
2、Spring Data Redis
2.1 介绍
SpringData是Spring中数据操作的模块,包含对各种数据库的集成,其中对Redis的集成模块就叫做SpringDataRedis,访问官网
- 提供了对不同Redis客户端的整合( Lettuce和Jedis)
- 提供了RedisTemplate统一API来操作Redis
- 支持Redis的发布订阅模型
- 支持Redis哨兵和Redis集群
- 支持基于Lettuce的响应式编程
- 支持基于JDK、JSON、字符串、Spring对象的数据序列化及反序列化
- 支持基于Redis的JDKCollection实现
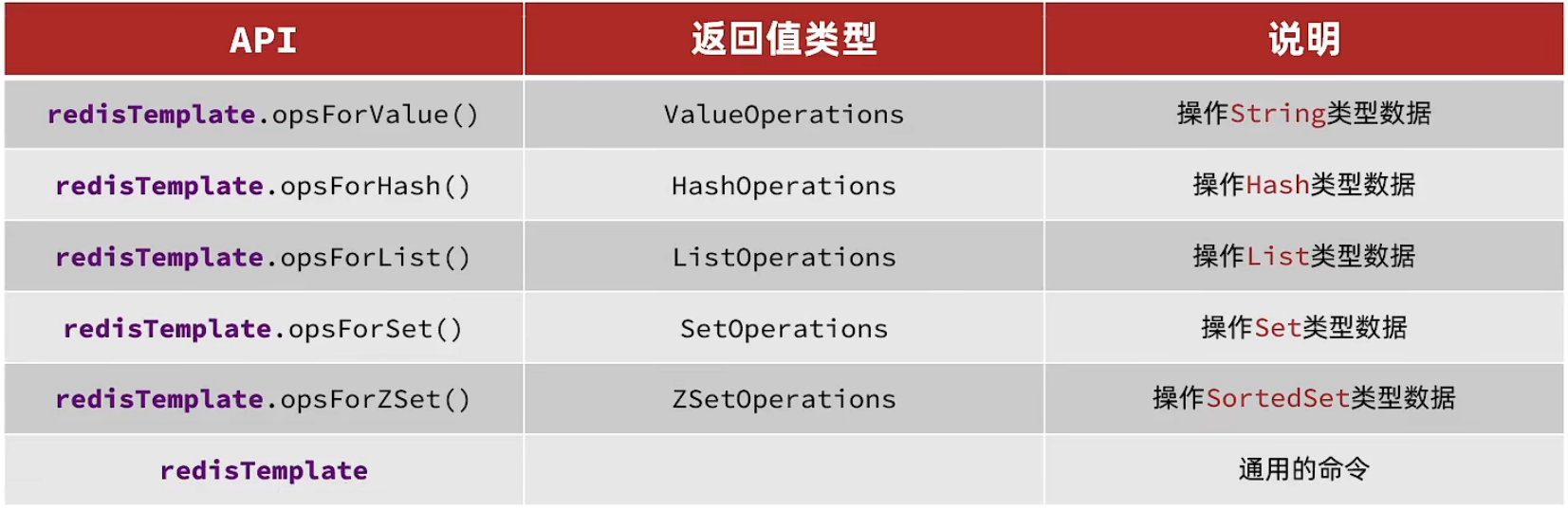
SpringDataRedis中提供了RedisTemplate工具类,其中封装了各种对Redis的操作。并且将不同数据类型的操作API封装到了不同的类型中,不同的数据对象使用不同的API避免臃肿的调用方法
2.2 使用方法
首先创建一个springboot工程,引入依赖
<!-- Spring Data Redis 依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- 连接池依赖 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
添加配置
spring.redis.host= 127.0.0.1
spring.redis.port= 6379
spring.redis.password= 123456
spring.redis.lettuce.pool.max-active= 8
spring.redis.lettuce.pool.max-wait= 100ms
spring.redis.lettuce.pool.max-idle= 8
spring.redis.lettuce.pool.min-idle= 0
定义一个用户类用来测试
public class User {
private String name;
private int age;
public User(){
}
public User(String name, int age){
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
代码调用,具体调用方法不做演示了,按照数据类型分类的命令
package com.heima.redisdemo;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
@SpringBootTest
class RedisDemoApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void contextLoads() {
redisTemplate.opsForValue().set("name","jerry");
redisTemplate.opsForHash().put("man","name","jok");
Boolean aBoolean = redisTemplate.opsForHash().hasKey("man", "name");
System.out.println(aBoolean);
}
@Test
void obj(){
User user = new User("tom",20);
redisTemplate.opsForValue().set("user:2",user);
User u = (User) redisTemplate.opsForValue().get("user:2");
System.out.println(u);
}
}
RedisTemplate可以接收任意Object作为值写入Redis,只不过写入前会把Object序列化为字节形式,默认是采用JDK序列化,得到的结果是这样的:
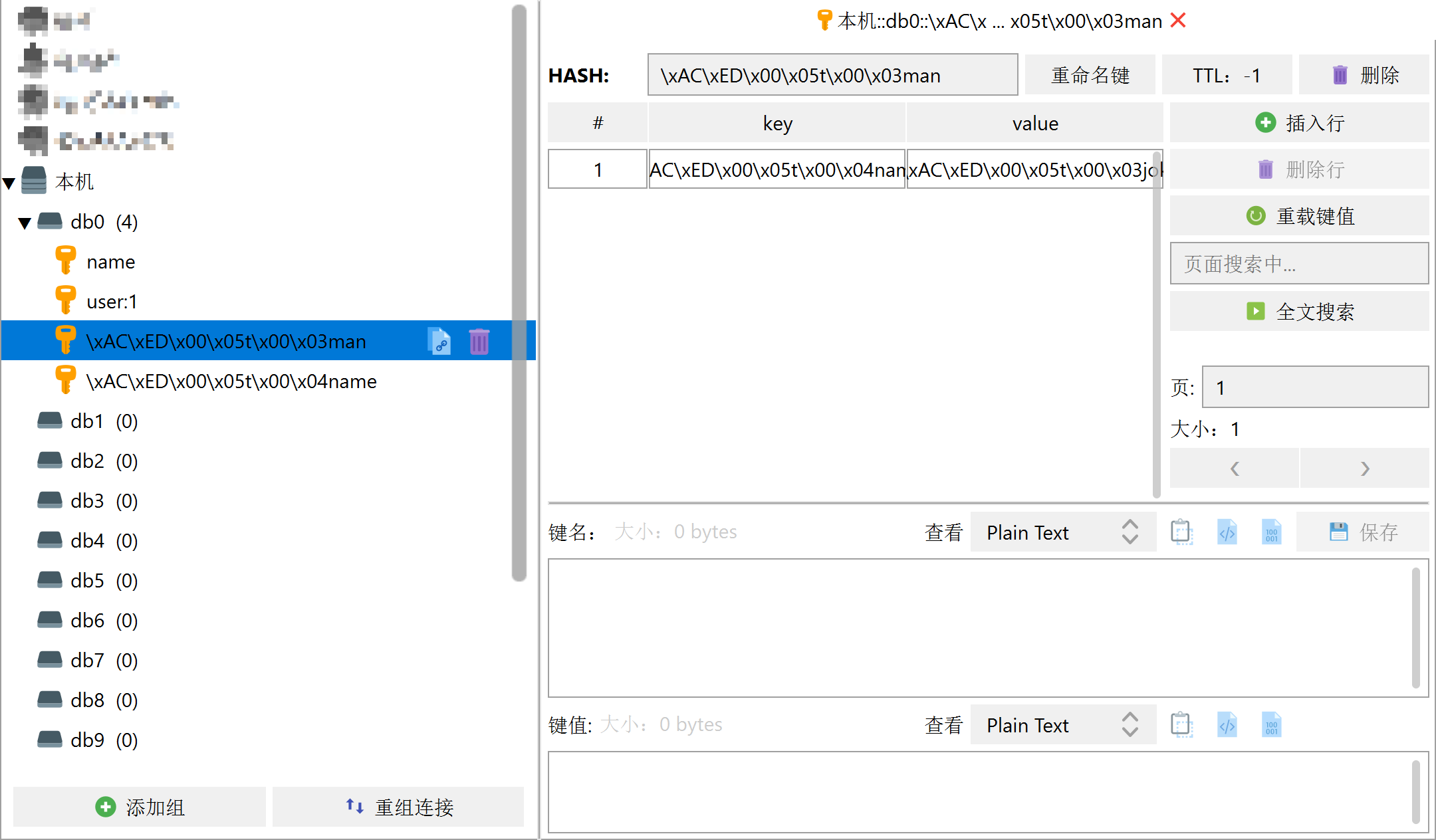
缺点:
- 可读性差
- 内存占用较大
但是这个是可以解决的,通过springDataRedis的序列化方式自定义解决
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory){
// 创建RedisTemplate对象
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
// 设置连接工厂
redisTemplate.setConnectionFactory(redisConnectionFactory);
// 创建JSON序列化工具
GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();
// 设置key的序列化
redisTemplate.setKeySerializer(RedisSerializer.string());
redisTemplate.setHashKeySerializer(RedisSerializer.string());
// 设置value的序列化
redisTemplate.setValueSerializer(jsonRedisSerializer);
redisTemplate.setHashValueSerializer(jsonRedisSerializer);
return redisTemplate;
}
}
注意需要依赖
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
再次运行上面代码的效果
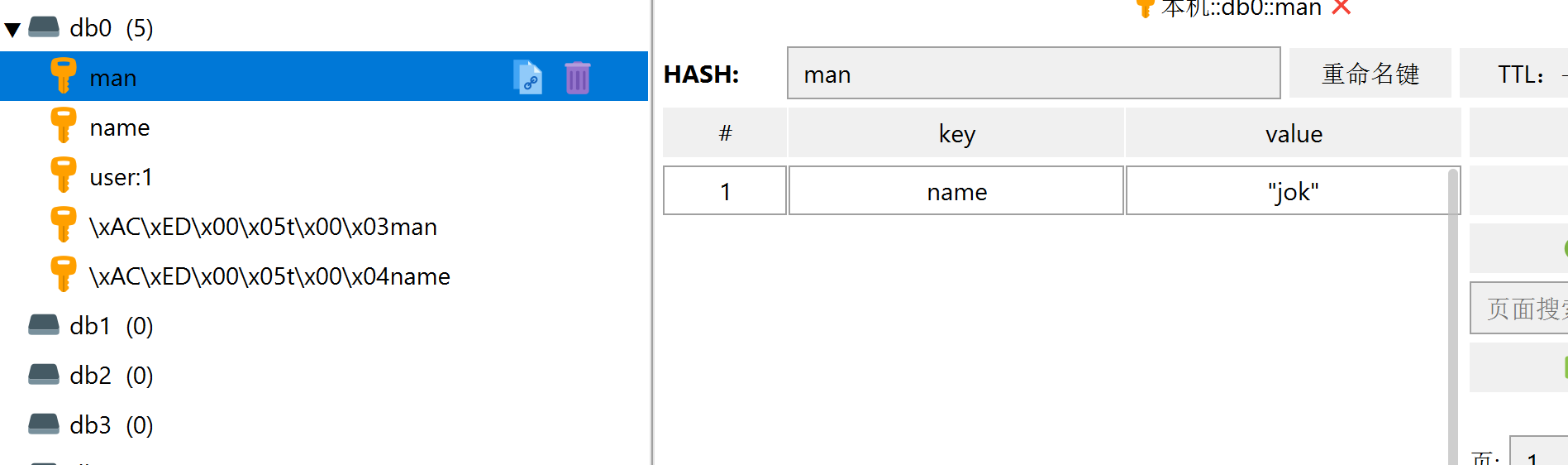
此时对象类数据会有多的数据字段@class,这个字段是序列化工具用来自动完成反序列化的,也就是下面这句代码需要用到的
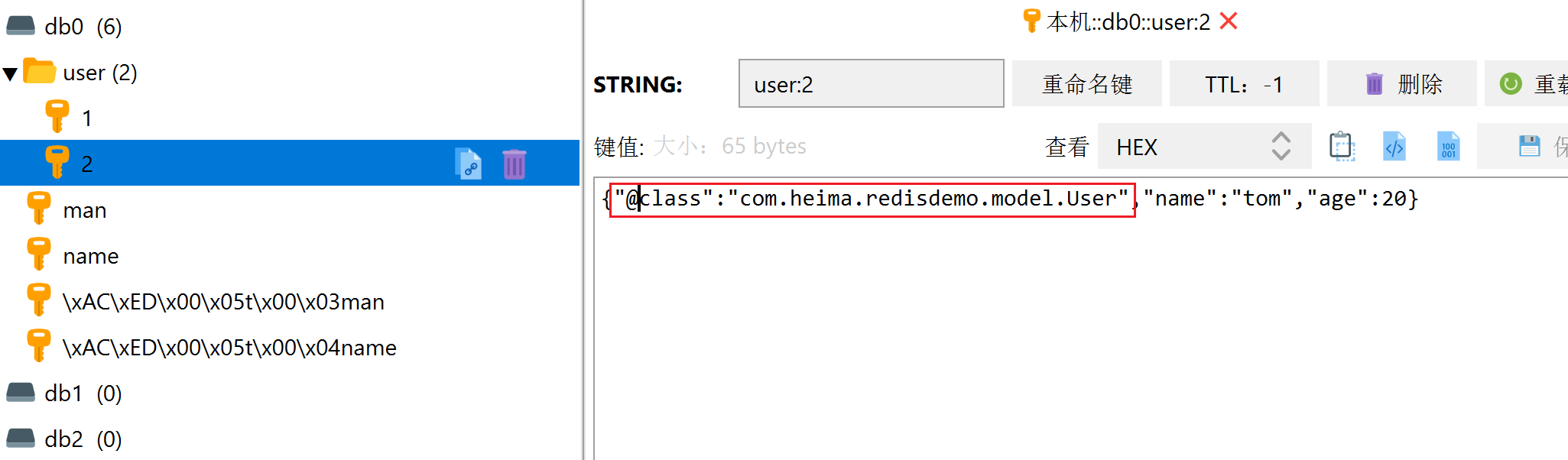
User u = (User) redisTemplate.opsForValue().get("user:2");
Spring默认提供了一个StringRedisTemplate类(经典白学之前的内容😂),它的key和value的序列化方式默认就是String方式。省去了我们自定义RedisTemplate的过程:
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Test
void contextLoads() {
stringRedisTemplate.opsForValue().set("name","jerry");
stringRedisTemplate.opsForHash().put("man","name","jok");
Boolean aBoolean = stringRedisTemplate.opsForHash().hasKey("man", "name");
System.out.println(aBoolean);
}
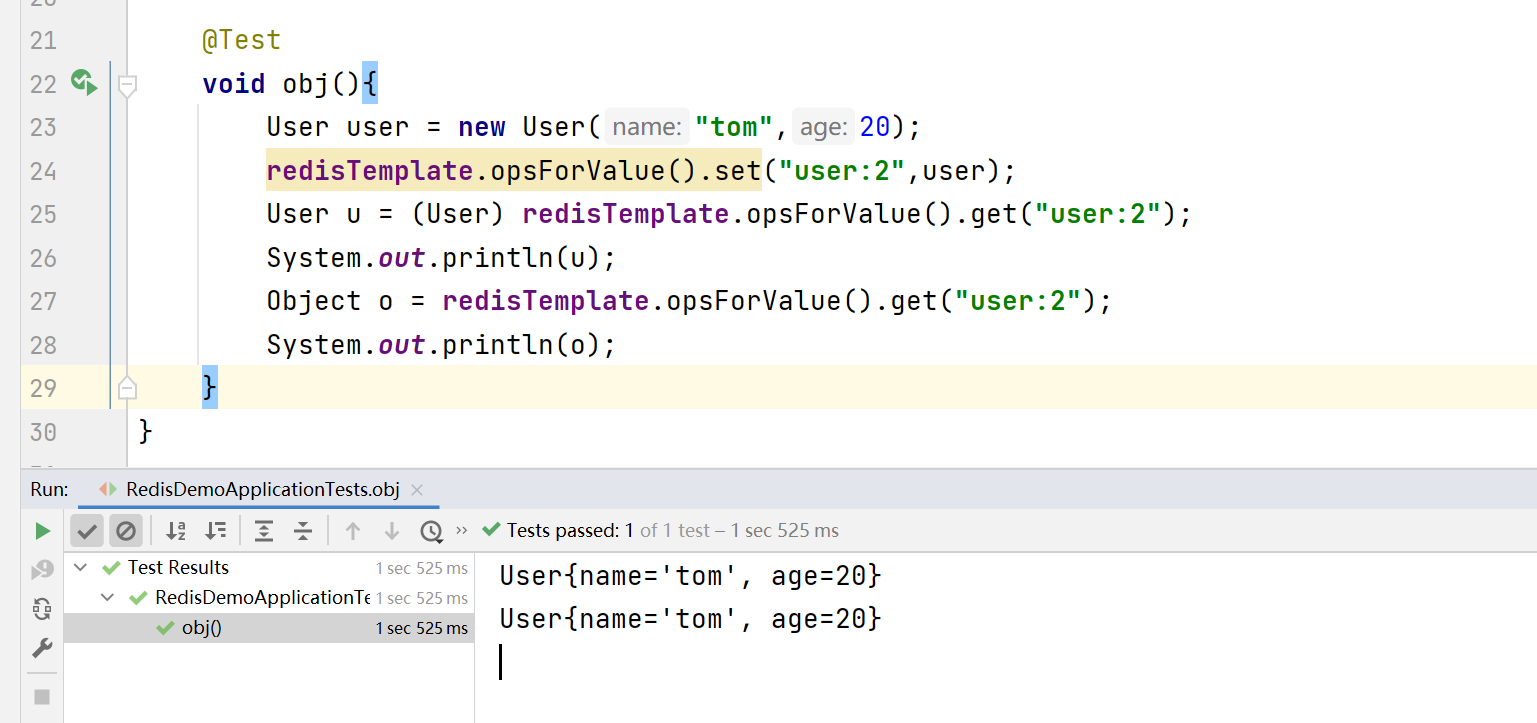
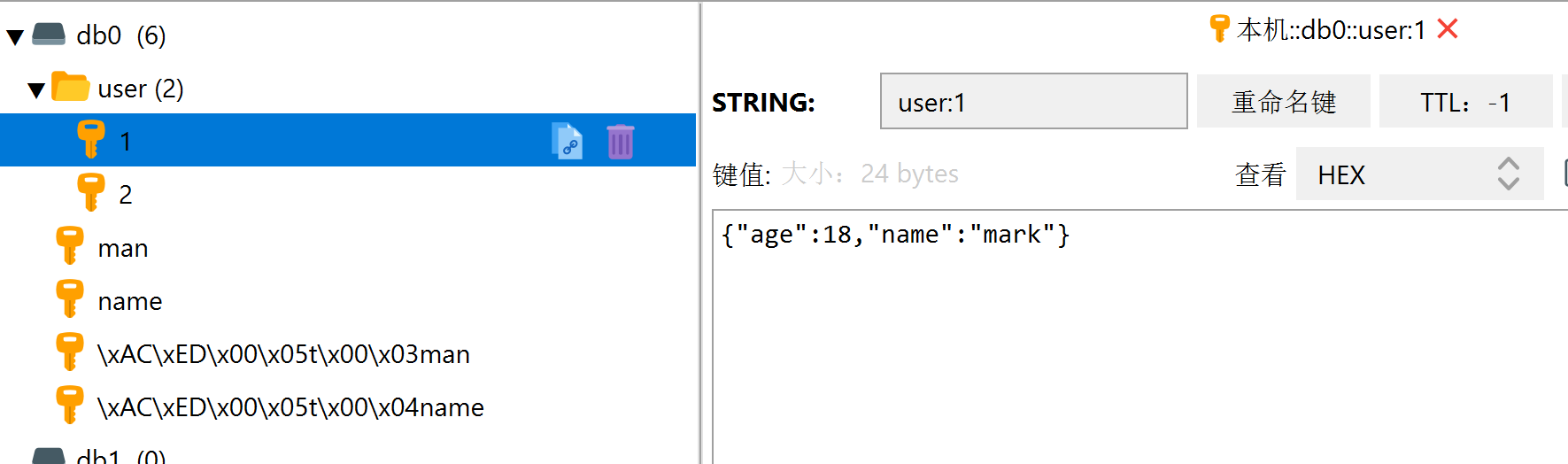
直接使用就可以,需要注意的是:使用StringRedisTemplate不能自动序列化与反序列化对象,需要手动序列化与反序列化,也就是下面这样
@Test
void doObj(){
User user = new User("mark", 18);
String s = JSONObject.toJSONString(user);
stringRedisTemplate.opsForValue().set("user:1",s);
String jsonUser = stringRedisTemplate.opsForValue().get("user:1");
User parse = JSONObject.parseObject(jsonUser, User.class);
System.out.println(parse);
}
最终结果是
总结
Spring Data Redis 在spring中使用更方法,兼容性也更好,需要注意的是springDataRedis的序列化方式自定义处理,当业务数据量比较大的时候,序列化存储对象中的@class占用内存量可能会非常多,建议使用StringRedisTemplate手动序列化而不是自动序列化