



记一次微信公众号文章抓取
目标
1、获取包含指定内容的公众号文章
2、将公众号文章保存至数据库
前置
1、有一个自己或者能使用的微信公众号
2、有一定的python编程能力
开始
一、获取基本信息
- 点击草稿箱 -> 新的创作 -> 新的图文 -> 进入到写文章页面点击引用按钮
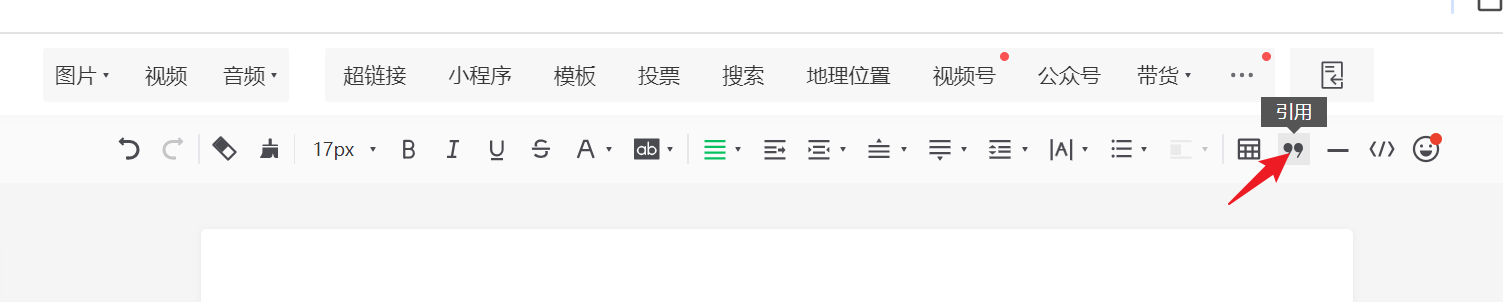
-
点击查找公众号文章,输入你要查询的公众号文章名称,点击查询
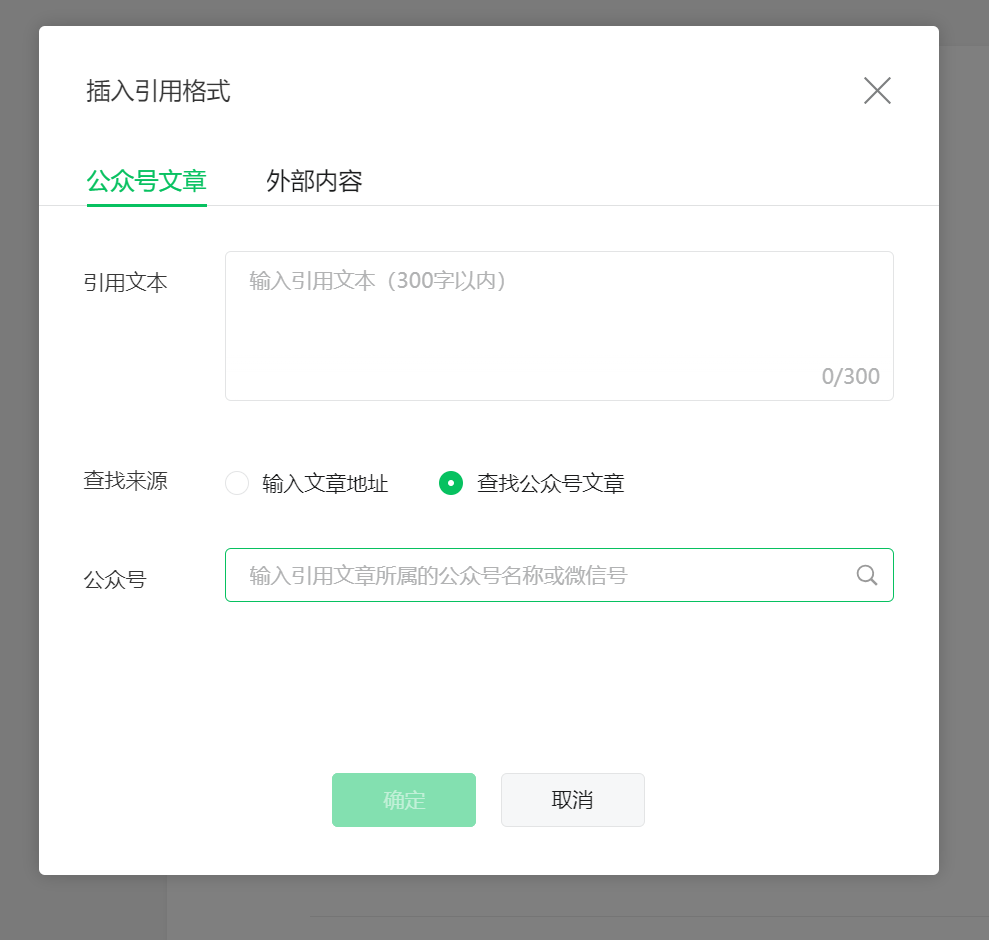
-
选择你要查询的公众号,按F12打开开发者模式,并点击
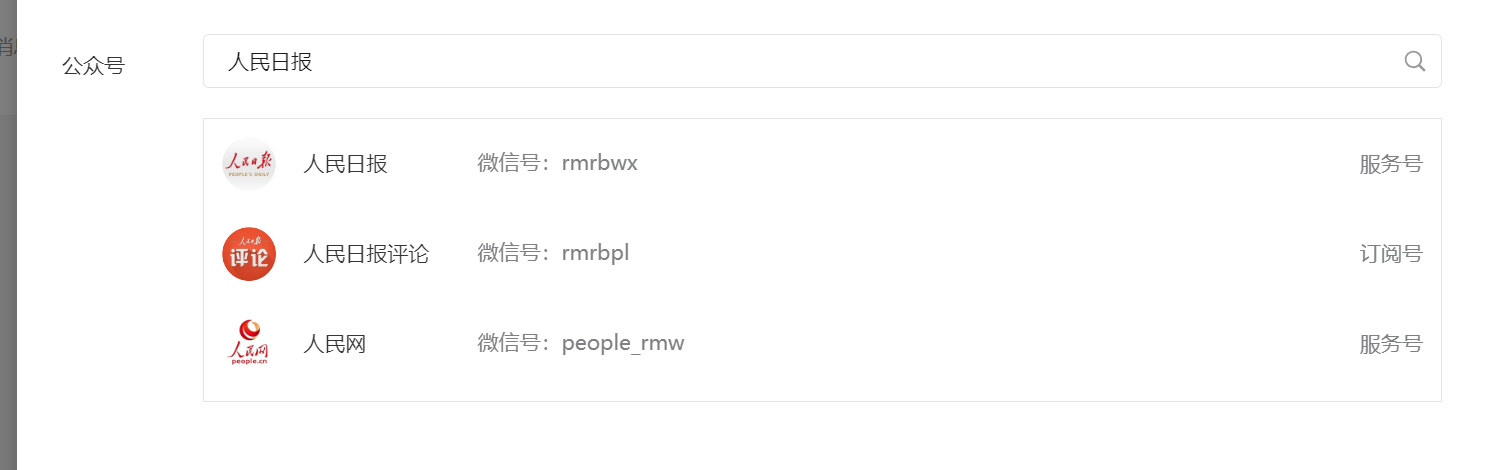
-
看到文章列表,找到对应的请求
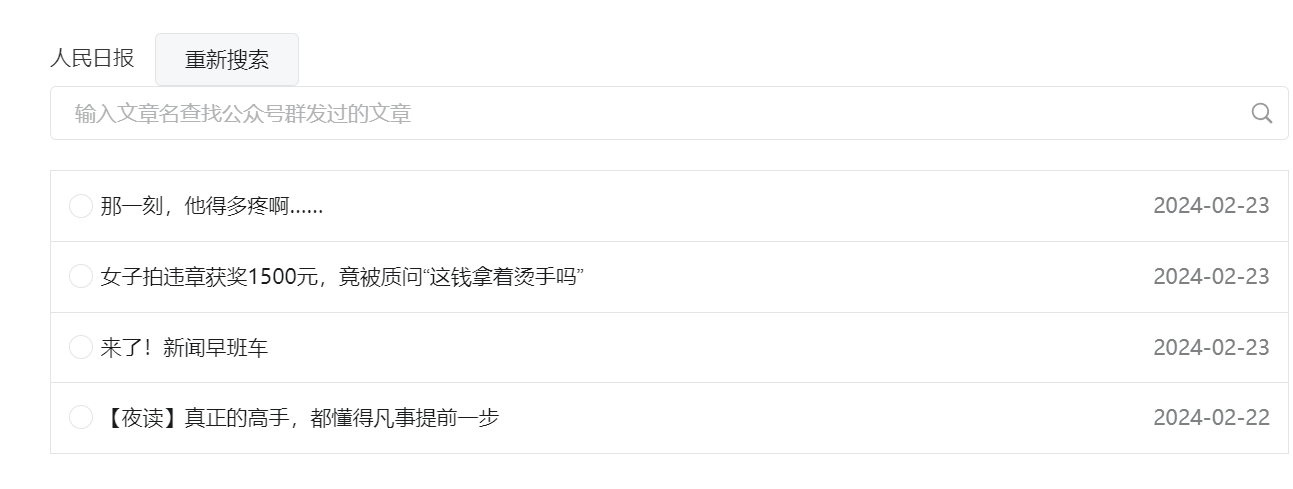
-
点击Network查看请求列表,找对应的请求,
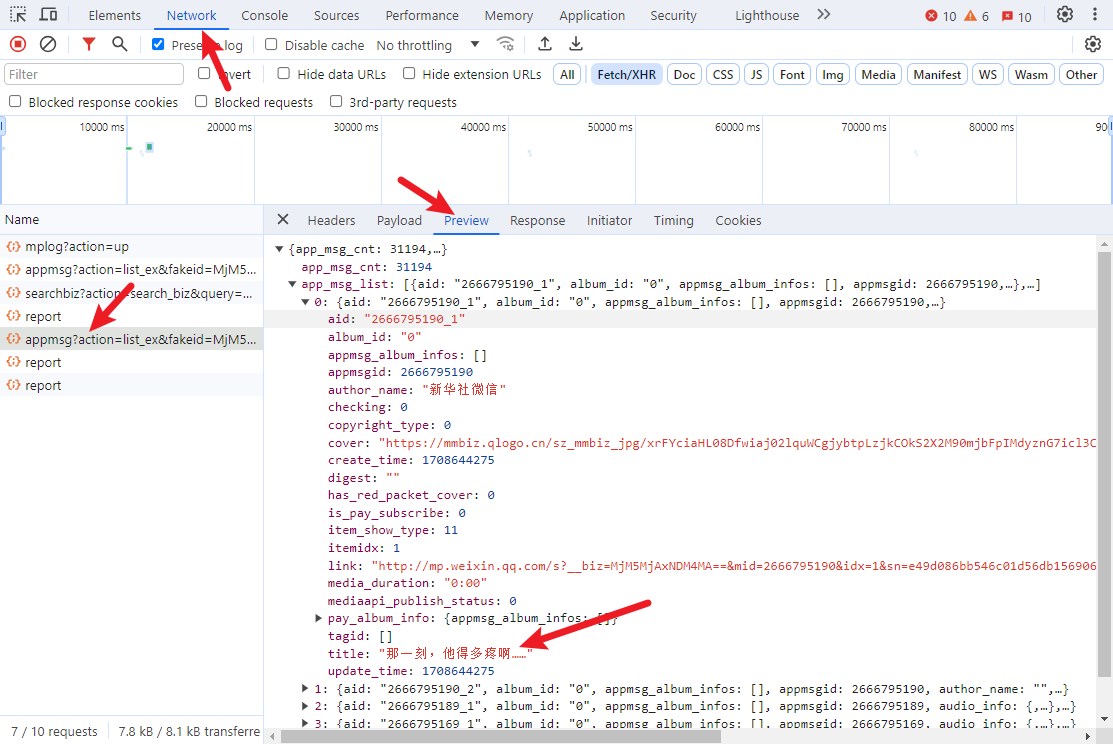
- 然后点击这个请求的payload,将fakeid和token记录下来,fakeid是我们需要查询的对应的公众号的信息,token是我们自己的登录信息。记录一次就可以了
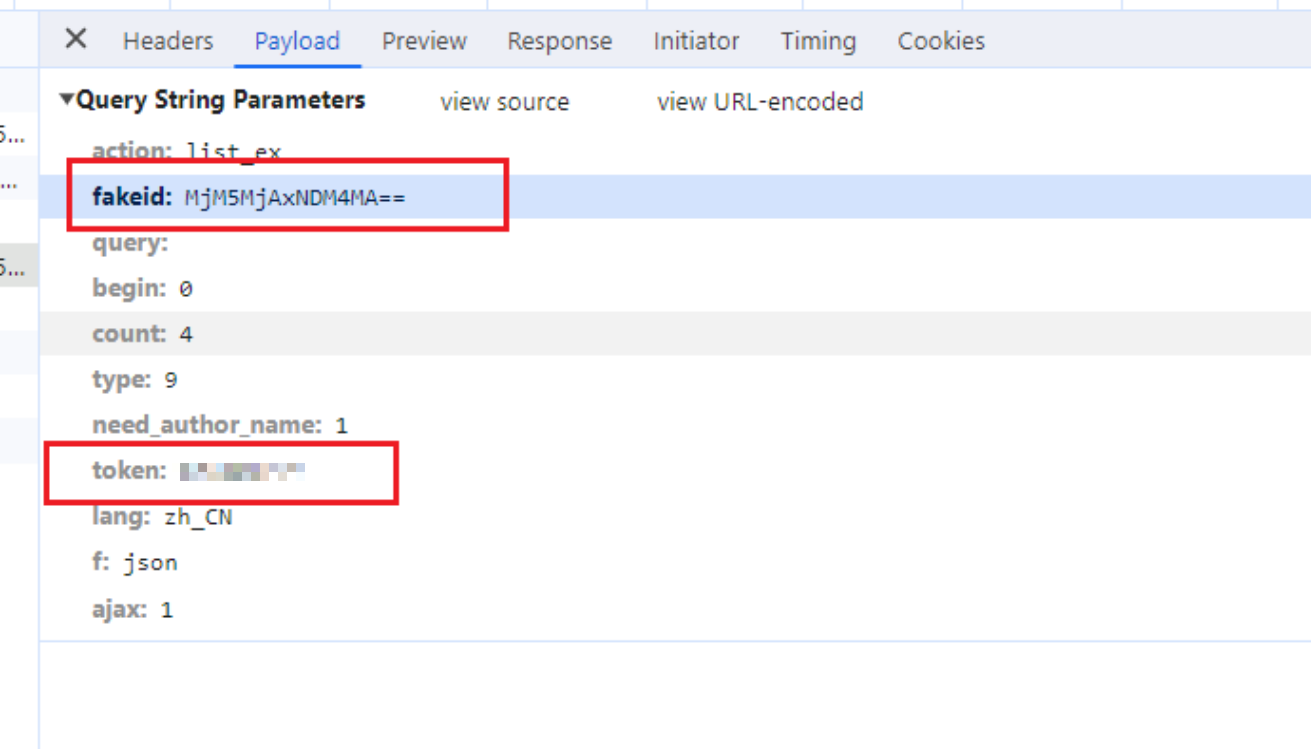
-
然后点击Headers,将自己的cookie记录下来,这里记录一个就可以了,因为这个自己的登录信息
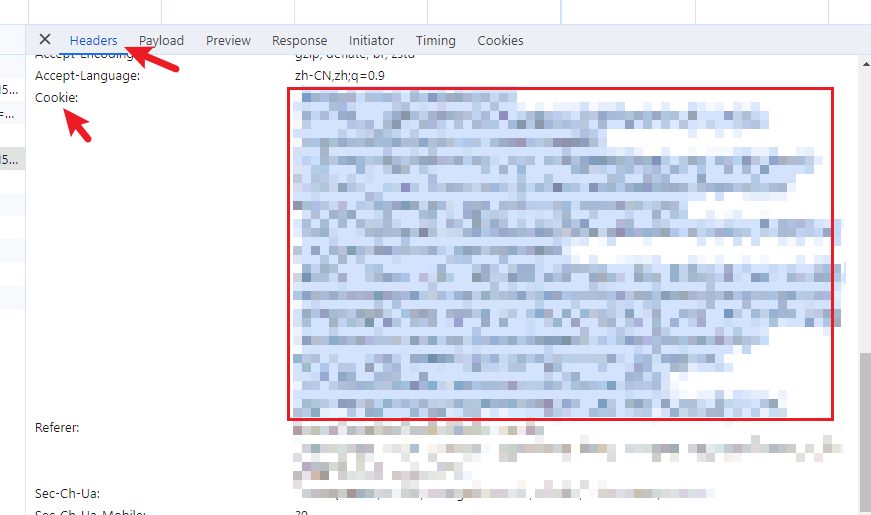
二、运行代码
这里不解释了,代码注释写了
主要逻辑
# -*- coding: utf-8 -*-
import datetime
import requests
import time
import config
from datetime import datetime
from bs4 import BeautifulSoup
# 两个工具类,文章下面有补充
from utils.dbUtils import mysqlUtils as db
from utils.drawingDBUtils import qiniuUtils
# 目标url
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
# 使用Cookie,跳过登陆操作
headers = {
"Cookie": config.COOKIE,
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36",
}
# 处理数据库存放结构
def make_data_obj(title, author, cover, synopsis, info_sources, info_url, content, release_time):
return {
'title': title,
'author': author,
'cover': qiniuUtils.upload_to_qiniu(cover, cover[cover.rfind("=") + 1:]),
'synopsis': synopsis,
'info_sources': info_sources,
'info_url': info_url,
'content': content,
'release_time': release_time,
'create_time': datetime.now(),
}
# 查询回来的文章对象
""""
{
"aid": "2658870927_1",
"album_id": "0",
"appmsg_album_infos": [],
"appmsgid": 2658870927,
"checking": 0,
"copyright_type": 0,
"cover": "https://mmbiz.qlogo.cn/sz_mmbiz_jpg/ibQ2cXpBDzUO30PiaMTpymX1DO8UfrZSJVBvSMksJqvKqQMcic0d6l9npiaMHxWLUbxthrylK2zYdU6dibsB0UnNTCg/0?wx_fmt=jpeg",
"create_time": 1688882993,
"digest": "",
"has_red_packet_cover": 0,
"is_pay_subscribe": 0,
"item_show_type": 11,
"itemidx": 1,
"link": "http://mp.weixin.qq.com/s?__biz=MjM5NzI3NDg4MA==&mid=2658870927&idx=1&sn=644b8b17ba102ebdc61b09a5991720ec&chksm=bd53f2e08a247bf6816c4ef12c2692785f9e95259c54eec20a1643eeff0a41822a1fa51f6550#rd",
"media_duration": "0:00",
"mediaapi_publish_status": 0,
"pay_album_info": {"appmsg_album_infos": []},
"tagid": [],
"title": "“现实版许三多”,提干了!",
"update_time": 1688882992
}
"""
# 获取文章
def do_acquire(number, fakeId, count, author):
"""
需要提交的data
以下个别字段是否一定需要还未验证。
注意修改yourtoken,number
number表示从第number页开始爬取,为5的倍数,从0开始。如0、5、10……
token可以使用Chrome自带的工具进行获取
fakeid是公众号独一无二的一个id,等同于后面的__biz
"""
data = {
"token": config.TOKEN,
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": number,
"count": count,
"query": "",
"fakeid": fakeId,
"type": "9",
}
# 使用get方法进行提交
content_json = requests.get(url, headers=headers, params=data).json()
article_list = []
now_time = datetime.now()
# 返回了一个json,里面是每一页的数据
for item in content_json["app_msg_list"]:
# 提取每页文章的标题及对应的url
dt = datetime.fromtimestamp(item["create_time"])
diff = now_time - dt
if diff.days <= config.QUERY_TIME_RANGE:
content = get_article_content(item["link"])
if filerInfo(content):
article_list.append(
make_data_obj(item["title"], author, item["cover"], "", author, item["link"], content, dt))
print(item["title"])
# 间隔5秒防止被封
time.sleep(5)
else:
break
return article_list
# 是否过滤
def filerInfo(info):
if config.IS_FILTER == 0:
for rule in config.KEY_WORDS:
flag = False
for keyWords in rule:
if keyWords in info:
flag = True
break
if not flag:
return False
return True
def do_query_list():
count = 5
for item in config.FAKE_ID_LIST:
num = 0
while True:
infoList = do_acquire(num, item['fakeId'], count, item['name'])
for info in infoList:
db.insert_info_reptile_data(info)
if count > len(infoList):
break
# 间隔10秒防止被封
time.sleep(10)
num += 5
# 将内容换成字符串类型
def get_article_content(url):
bf = get_beautiful_soup(url)
div = bf.find(id='page-content')
js_content = div.find(id='js_content')
js_content['style'] = 'visibility: initial'
filter_tag_src(div)
return str(div)
# 过滤图片资源
def filter_tag_src(div):
list = div.find_all('img')
if len(list) > 0:
for item in list:
if item.has_attr('data-src') and item.has_attr('data-type'):
new_src = qiniuUtils.upload_to_qiniu(item['data-src'], item['data-type'])
del item['data-src']
del item['data-type']
item['src'] = new_src
return
# 解析url
def get_beautiful_soup(url):
res = requests.get(url)
res.encoding = 'utf-8'
html = res.text
return BeautifulSoup(html, "html5lib")
if __name__ == '__main__':
do_query_list()
# 请求的cookie
COOKIE = 'xxx'
# 请求的token
TOKEN = 'xxx'
# 需要查询的公众号列表
FAKE_ID_LIST = [
{
'name': '珠海市租房群',
'fakeId': 'MzIwMTcxMjgyMw=='
},
{
'name': '珠海不求人',
'fakeId': 'MzIyMTE5ODkyOA=='
},
{
'name': '珠海租房汇总',
'fakeId': 'MzUxNDgxODg2Mg=='
},
{
'name': '珠海租房论坛',
'fakeId': 'MzU0MDAxMTkwOQ=='
},
{
'name': '珠海执优租房',
'fakeId': 'MzU4MDIyMzU4Mg=='
}
]
# 是否过滤 0 否, 1 是
IS_FILTER = 0
# 过滤条件,一级的数组需要都满足,二级的数组满足一个即可
KEY_WORDS = [
['两室','两厅'],
['金湾'],
['电梯']
]
# 查询时间范围的,0为今天,1昨天到今天,2前天到今天,以此类推
QUERY_TIME_RANGE = 1
补充两个工具类
-
数据库工具
from peewee import * from playhouse.pool import PooledMySQLDatabase # 连接到 MySQL 数据库 database = PooledMySQLDatabase( 'ruoyi', max_connections=10, stale_timeout=300, host='127.0.0.1', port=3306, user='ruoyi', password='123456' ) # 定义数据模型 class InfoReptileData(Model): id = BigAutoField(primary_key=True) # 将类型改为 BigAutoField title = CharField() author = CharField() synopsis = CharField() info_sources = CharField() info_url = CharField() release_time = DateTimeField() create_time = DateTimeField() content = TextField() cover = CharField() class Meta: database = database table_name = 'info_reptile_data' class InfoReptileDataContent(Model): id = BigAutoField(primary_key=True) # 将类型改为 BigAutoField info_id = CharField() content = TextField() sort_id = CharField(null=True) create_time = DateTimeField(null=True) update_time = DateTimeField(null=True) class Meta: database = database table_name = 'info_reptile_data_content' def close_data_base(): # 关闭数据库连接 database.close() # 定义方法插入数据到 info_reptile_data 表并返回插入数据的id def insert_info_reptile_data(data): if database.is_closed(): # 连接数据库 database.connect() # 创建表(如果不存在) database.create_tables([InfoReptileData]) try: with database.atomic(): info_reptile_data = InfoReptileData.create(**data) inserted_id = info_reptile_data.id return inserted_id except Exception as e: print(f"Failed to insert data into 'info_reptile_data': {str(e)}") return None # 定义方法插入数据到 info_reptile_data_content 表并返回插入数据的id def insert_info_reptile_data_content(data): if database.is_closed(): # 连接数据库 database.connect() database.create_tables([InfoReptileDataContent]) try: with database.atomic(): info_reptile_data_content = InfoReptileDataContent.create(**data) inserted_id = info_reptile_data_content.id return inserted_id except Exception as e: print(f"Failed to insert data into 'info_reptile_data_content': {str(e)}") return None -
七牛云图片云床
import random from datetime import datetime import requests from qiniu import * # 调用示例,需要改成你自己的 access_key = 'your_access_key' secret_key = 'your_secret_key' bucket_name = 'your_bucket_name' domain = 'your_domain' def upload_to_qiniu(url, type): file_name = get_file_name(type) # 创建 Auth 对象 auth = Auth(access_key, secret_key) # 生成上传 Token token = auth.upload_token(bucket_name, file_name) # 从链接下载文件数据 response = requests.get(url) file_data = response.content # 上传文件数据 ret, info = put_data(token, file_name, file_data) # 打印上传结果信息 # print(ret) # print(info) # 构建文件访问链接 if 'key' in ret: file_key = ret['key'] file_url = f"{domain}/{file_key}" # 替换为实际的文件访问链接 return file_url else: return None def get_file_name(type): # 格式化当前时间 formatted_name = datetime.now().strftime("%Y-%m-%d_%H-%M-%S") + "_" + generate_random_numbers(6) + "." + type return formatted_name def generate_random_numbers(length): # 生成指定长度的随机数字串 random_numbers = [str(random.randint(0, 9)) for _ in range(length)] # 组合随机数字为字符串 random_numbers_string = ''.join(random_numbers) return random_numbers_string # 测试一下 if __name__ == '__main__': url = upload_to_qiniu("https://mmbiz.qpic.cn/mmbiz_png/ibQ2cXpBDzUNwMa2x7AtzVF1qLLNsQmqgGYUuOZxrQiavO6DmZOmwBudmjmg6jkJEpAJJAutmgmUiaYn4obZH0WtQ/640?wx_fmt=png&wxfrom=5&wx_lazy=1&wx_co=1", "png") print(url)三、运行
注:如果开启过滤了,这里只会打印出过滤后的结果
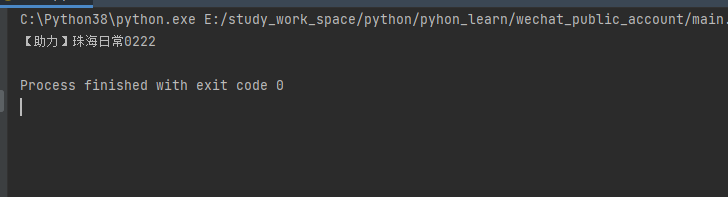
补充
版本信息
python 3.8.8.rcl
requests 2.28.2
beautifulsoup4 4.12.2
peewee 3.16.2
qiniu 7.10.0
参考文章
记一次微信公众号爬虫的经历(微信文章阅读点赞的获取):链接
评论区